4. Cloud Infra Automation Framework Developer Guide¶
4.1. Introduction¶
Cloud Infra Automation Framework (aka engine) supports provisioning of compute resources, deployment of various stacks, and testing on them. The stacks that are currently supported by the framework are
Kubernetes
ONAP
Openstack
Due to the differences in how these stacks are deployed, it is important to keep the core of the engine agnostic to the stacks. This is achieved by pushing stack specific steps into stacks themselves while keeping functionality that is common across different stacks within the core itself.
In addition to engine core and stacks, the framework utilizes various tools to provision resources and install stacks. These tools are also separated from the core itself so they can be used by different stacks without coupling them tightly with the core of the stacks themselves.
The diagram below shows the architecture of the framework on a high level.
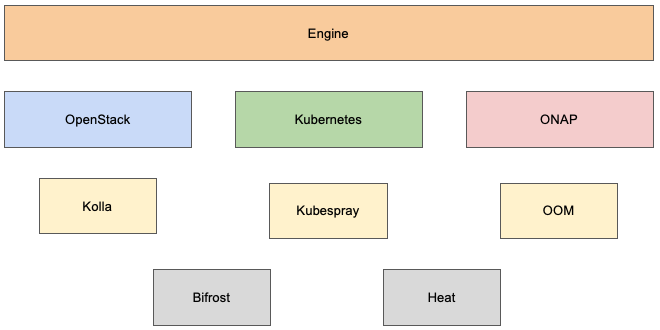
4.2. Engine Components¶
4.2.1. Engine Core¶
This is the core of the framework which drives the packaging, provisioning of the compute resources, and installation of stacks.
The responsibilities of the core are
user interface: Users use the main packaging and deployment scripts developed within engine to drive the packaging and deployment without needing to know what tool they should be using
preparation of stacks: Depending on what the user wants to deploy, the core pulls in the stack based on the version specified by the user and makes basic preparation
execution of stack install script: Once the dependencies are pulled in, the core then executes stack install script and gives control to it
execution of stack packaging script: If the framework is running in packaging mode, the core executes stack packaging script and gives control to it
provisioning of engine services: Engine core hosts the functionality to provision engine services for offline deployments that are common across different stacks. The actual provisioning is performed by the stacks themselves and not the core
providing common libraries: The libraries common across stacks such as libraries for packaging and deployment are kept within engine core
Multiple stacks are supported by engine and the stack to package and/or deploy can be controlled using -s switch. This then sets the corresponding environment variable, STACK_TYPE, so the core can clone that stack during the preparation.
The framework supports multiple versions of same stack so the users can deploy the version they need. This is enabled by the use of -v switch to engine core which sets corresponding environment variable for the stack to be deployed, STACK_VERSION. This results in engine core to clone that version of the stack during preparation phase.
If the engine is executed as part of CI/CD for verification purposes, third environment variable is also exposed, STACK_REFSPEC, so the change that is sent to stack can be verified properly. Please note that it is not possible to set this variable on the command line as it is internal to engine. However, it can still be used if one wants to test a change that’s on Gerrit locally by setting the variable manually on shell before executing deploy.sh.
4.2.2. Stacks¶
Stacks are the blocks within the framework that host and perform stack specific functions such as identifying the provisioner and installer to use, scenario to deploy the stack with, keep list of dependencies to package for offline deployments, and actually perform the packaging.
The responsibilities of the stacks are
interface to engine: The scripts install.sh and package.sh are the interface between the stacks and engine core
determining the provisioner: Stack determines the provisioner to use by analysing the provided PDF file. If a libvirt or baremetal PDF is passed to the framework, it results in the use of Bifrost. If a Heat environment file is passed as PDF to the framework, stack sets Heat as the provisioner.
determining the installer: The installer used by the stack is specific within stack configuration file (eg vars/kubernetes.yaml). Stack then sets installer accordingly.
preparation of provisioner and installer: Based on what is determined in earlier steps, stack prepares corresponding tools by pulling their repositories based on the versions
execution of provisioner: After the completion of the preparation, provision script of the identified provisioner is executed
execution of installer: After the completion of the provisioning, install script of the identified installer is executed
packaging: Stack dependencies are packaged by the stacks themselves as what is needed for different stacks for offline deployments do not match
provisioning of engine services: When run in offline mode, the provisioning of engine services are executed by the stacks even though the actual functionality is developed within engine core
As noted in Engine core section, multiple versions of stacks are supported. This in turn means that multiple versions of provisioners and installers are supported so the stack can pick the right version of the tool to use for given stack version. The mapping between the stacks and the tools are controlled within stack configuration file and it is important the versions of the stacks and the tools map correctly. Otherwise a given version of the stack may not be possible to deploy due to compatibility issues.
4.2.3. Provisioners¶
Provisioners are just the tools to provision the resources using and they do not contain stack or installer specific functionality. (this may not be the case at the moment but it will be refactored over time to make them fully agnostic)
Provisioners generally do not branch after stacks as they do not have any relation to actual stack versions. Thus, provisioners have single branch/version that can be used by whatever stack. The mapping between stacks/versions and provisioners/versions are controlled within stack configuration files.
4.2.4. Installers¶
Installers are the tools that installs selected stack on provisioned resources. Even though they are very stack oriented, they can still be used by multiple stacks.
Installers branch after stacks so the stacks can use the compatible versions of the installers. The mapping between stacks/versions and installers/versions are controlled within stack configuration files.
4.3. Scenarios¶
Scenarios are very specific to the stacks even though they are closely related to installers themselves. In order to handle differences across various stacks, the scenarios are developed within stack repositories rather than installers. (this is TBD)
An example could explain why this is like this. Kubernetes is needed by both Kubernetes stack itself and by ONAP. But the configuration of Kubernetes differs between stacks. One of the differences is that the Kubernetes deployment needed by ONAP requires shared storage but vanilla Kubernetes does not. Differences such as this can be handled within the stacks themselves.
4.4. Developing New Features or Bugfixes¶
It is frequently necessary to develop new features for the framework. With the introduction of stacks, provisioners, and installers, where this work needs to be done heavily depends on what is being done.
The rule of thumb is - if you need to develop a new feature, it must always be done on master branch first and then cherrypicked to all the active branches. There may be cases that some bugs impact on certain versions or a functionality is needed for a specific version. If this is the case, it would be better to have a quick discussion with the team to determine where you can do that change rather than sending change to a master branch or a maintenance branch.
Here are some other examples.
developing new feature for engine core: The features developed for the engine core impact all the stacks. Engine core follows one track approach so the change just needs to be done on master branch.
developing new feature for a specific stack: Since multiple versions of the stacks are supported by the framework, a feature might need to be developed on multiple branches. If this is the case, the change first must be sent to master branch and cherrypicked to other branches once the verification passes. In some cases the features needed by the stacks may need to be developed within provisioner or installer repository. In this case, same thing is needed - the change is done on master branch first and then cherrypicked to other branches accordingly.
developing scenarios: The scenarios are developed and hosted within stack repositories. If what is developed is an existing scenario and it is expected to be used by stack versions other than master, the change needs to go to master and then cherrypicked to other branches. If it is totally a new scenario and should be available for a certain version of the stack, the development can be done on master branch and cherrypicked to only the corresponding branch.
4.4.1. Testing Your Changes¶
It is always good to test your changes before you send them to Gerrit for review or verification by CI. The level of testing you can do depends on the nature of the change but no matter the complexity of the change, it is always important to run static code analysis before sending the change for review. Further local testing such as deployment and testing is good and important as well but it may not be necessary for all cases.
Local Testing
Engine will pull various repositories as required for the specific stack and scenario requested. To test out local changes to these repositories, Engine allows you to supply additional parameters to Ansible via the environment variable ENGINE_ANSIBLE_PARAMS. This can be used to override the locations and versions of the various repositories used by Engine. When using this, be sure to also specify the environment variable ANSIBLE_HASH_BEHAVIOUR=merge.
To ensure Engine uses local versions of these repositories:
Create a local variables file (e.g. ${HOME}/local_vars.yml) that specifies the local path for each of the repositories you wish to test:
---
stacks:
kubernetes:
src: "file:///path/to/your/copy/of/stack/kubernetes"
version: "master"
provisioners:
bifrost:
src: "file:///path/to/your/copy/of/provisioner/bifrost"
version: "master"
installers:
kubespray:
src: "file:///path/to/your/copy/of/installer/kubespray"
version: "master"
Amend the command you would normally use to run deploy.sh by prepending the following arguments:
ENGINE_ANSIBLE_PARAMS="-e @/path/to/your/local_vars.yml" ANSIBLE_HASH_BEHAVIOUR=merge ./deploy.sh ...
The above invocation of deploy.sh will now pull your local versions of the specified repositories, instead of the default location.
When testing in offline mode (-x), additional actions are necessary to keep the offline repositories under /opt/engine/offline in sync. A script similar to the following can be used to ensure your local changes are used:
# Change SYNC_BRANCH as required
SYNC_BRANCH="master"
declare -A REPO_MAP
# Change BASEDIR as required
BASEDIR="${HOME}"
REPO_MAP["${BASEDIR}/src/nordix/infra/stack/kubernetes"]="/opt/engine/offline/git/engine-kubernetes"
REPO_MAP["${BASEDIR}/src/nordix/infra/installer/kubespray"]="/opt/engine/offline/git/engine-kubespray"
REPO_MAP["${BASEDIR}/src/nordix/infra/provisioner/heat"]="/opt/engine/offline/git/engine-heat"
REPO_MAP["${BASEDIR}/src/nordix/infra/stack/onap"]="/opt/engine/offline/git/engine-onap"
REPO_MAP["${BASEDIR}/src/nordix/infra/installer/oom"]="/opt/engine/offline/git/engine-oom"
for REPO_SRC in "${!REPO_MAP[@]}"; do
REPO_DEST="${REPO_MAP[$REPO_SRC]}"
if [ ! -d "${REPO_SRC}" ]; then
echo "${REPO_SRC} does not exist, skipping"
continue
fi
if [ ! -d "${REPO_DEST}" ]; then
echo "${REPO_DEST} does not exist, skipping"
continue
fi
echo "${REPO_DEST}:${SYNC_BRANCH} <-- ${REPO_SRC}:${SYNC_BRANCH}"
(
cd "${REPO_DEST}"
git remote rm dev || true
git remote add dev "file://${REPO_SRC}"
git fetch dev
git reset --hard dev/${SYNC_BRANCH}
)
done
Simply run this script prior to running deploy.sh.
Static Code Analysis
Engine bash scripts, Ansible playbooks, and other YAML files are subject to static code analysis using various utilities listed below.
It is always a good idea to test your changes locally before sending them for code review and for further testing in order to receive fastest possible feedback and also to avoid unnecessary failures on CI.
Install python and virtualenv
sudo apt install -y python3-minimal virtualenv
Create and activate virtualenv
virtualenv -p python3 .venvsource .venv/bin/activate
Install test requirements
pip install -r test-requirements.txt
Use tox to run static code analysis
4a. Run all tests
tox4b. Run ansible-lint
tox -e ansible-lint4c. Run shellcheck
tox -e shellcheck4d. Run yamllint
tox -e yamllint4e. Run multiple checks using comma seperated list
tox -e ansible-lint,shellcheck4f. If you updated the documentation in infra/engine repo, run docs checks
tox -e docs
4.5. Verifying Changes¶
When a change is sent to Gerrit for any part of the framework, it gets tested by the jobs on Jenkins. The types of tests depend on which component the change is sent for but here is the list of tests on a high level, followed by more detailed information.
static analysis: All the changes that are sent to any of the repositories must pass static analysis. Ansible lint, yamllint, and shellcheck are what is currently used for static analysis.
packaging: The changes must not break packaging functionality
deployment: The changes must not break deployment functionality - both in online and offline modes
testing: The changes mush not break the stack functionality. OPNFV Functest Healthcheck is used to ensure the basic stack functionality still works.
The jobs on Jenkins block what comes after them. This is implemented in order to catch faults as soon as possible and provide feedback to the developers.
Static analysis jobs are the first jobs that get triggered for changes that are sent to any repository. Rest of the jobs are blocked until the successful completion of static analysis. If static analysis fails, the other jobs will be aborted as there is no point running the rest since the failures in static analysis is so basic and must be fixed before attempting even more extensive testing.
Upon successful completion of static analysis, packaging job gets triggered. Similar to static analysis, packaging job also blocks the rest of the deployment and test jobs. The reason for this is that we must always keep packaging functionality working due to requirement to support offline deployments. If packaging fails, the rest of the jobs are aborted.
As final step, deployment and testing are run in both online and offline modes. Online mode ensures that whatever version of the stack or the tools that are pulled in during the deployment works in a similar environment as upstream with no limitations. This is especially important for moving to newer versions of stacks and/or tools. Offline mode ensures that whatever that is packaged within the offline dependencies file can be used to deploy and use the given version of the selected stack within an airgapped environment.
4.5.1. Engine Core and Provisioner Changes¶
These jobs verify changes coming to
infra/engine
infra/provisioner/bifrost
infra/provisioner/heat
repositories and only for master branch as the engine core and provisioners follow trunk based development.
Engine core and provisioner changes are verified as below.
static analysis: all the changes coming to these repositories are tested using ansible-lint, yamllint, and shellcheck. In addition to these, docs verification is also done for the changes that update documentation. But it is only run for the changes coming to infra/engine repo as the documentation is hosted in this repo.
packaging: Testing the packaging functionality.
online deployment on libvirt instances: Testing the provisioning of the compute resources using bifrost and deployment using the installer in online mode.
online deployment on Heat instances: Testing the provisioning of the compute resources using heat and deployment using the installer in online mode.
offline deployment on libvirt instances: Testing the provisioning of the compute resources using bifrost and deployment using the installer in offline mode using the package produced in previous step.
offline deployment on Heat instances: Testing the provisioning of the compute resources using heat and deployment using the installer in offline mode using the package produced in previous step.
Please note that the default stack for this pipeline is Kubernetes and the default scenario is k8-multus-plugins.
4.5.2. Kubernetes Changes¶
These jobs verify changes coming to
infra/stack/kubernetes
infra/installer/kubespray
repositories and all the active branches.
static analysis: all the changes coming to these repositories are tested using using ansible-lint, yamllint, and shellcheck.
packaging: Testing the packaging functionality.
online deployment on libvirt instances: Testing the provisioning of the compute resources using bifrost and deployment using the installer in online mode.
online deployment on Heat instances: Testing the provisioning of the compute resources using heat and deployment using the installer in online mode.
offline deployment on libvirt instances: Testing the provisioning of the compute resources using bifrost and deployment using the installer in offline mode using the package produced in previous step.
offline deployment on Heat instances: Testing the provisioning of the compute resources using heat and deployment using the installer in offline mode using the package produced in previous step.
Please note that the default scenario is k8-multus-plugins.
4.5.3. ONAP Changes¶
These jobs verify changes coming to
infra/stack/onap
infra/installer/oom
repositories and all the active branches.
static analysis: all the changes coming to these repositories are tested using using ansible-lint, yamllint, and shellcheck.
packaging: Testing the packaging functionality.
online deployment on Heat instances: Testing the provisioning of the compute resources using heat and deployment using the installer in online mode.
offline deployment on Heat instances: Testing the provisioning of the compute resources using heat and deployment using the installer in offline mode using the package produced in previous step.
Please note that the default scenario is onap-full-nofeature.
Deployment and testing on libvirt resources provisioned using bifrost is not tested as the baremetal deployments of ONAP is not enabled yet.
4.5.4. OpenStack Changes¶
These jobs verify changes coming to
infra/stack/openstack
infra/installer/kolla
repositories and all the active branches.
static analysis: all the changes coming to these repositories are tested using using ansible-lint, yamllint, and shellcheck.
packaging: Testing the packaging functionality.
online deployment on libvirt instances: Testing the provisioning of the compute resources using bifrost and deployment using the installer in online mode.
offline deployment on libvirt instances: Testing the provisioning of the compute resources using bifrost and deployment using the installer in offline mode using the package produced in previous step.
Please note that the default scenario is os-nosdn-nofeature.
Deployment and testing on OpenStack resources provisioned using heat is not tested as the cloud deployments of OpenStack is not supported.
4.6. Releases¶
TBD
4.7. References¶
TBD